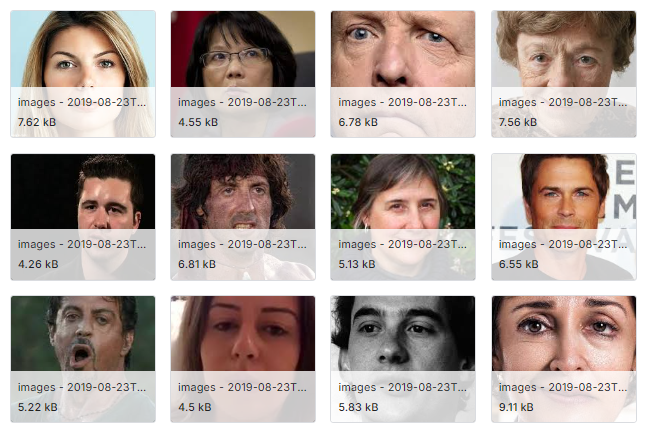
The online data repository Kaggle has removed a problematic dataset for violating intellectual property rights months after it was flagged by sleuths for containing celebrity photos and lacking information on data provenance or confirmed medical diagnoses.
Researchers had used the images to train machine learning algorithms to detect stroke, but the dataset instead contained images of people with Bell’s palsy — as well as pictures of celebrities from movies and on the red carpet, as we reported in May. Adrian Barnett, a medical statistician at Queensland University of Technology in Australia, flagged the dataset after discovering two others he and his colleagues investigated in a February preprint that showed signs of being fabricated.
Using a reverse image search, Barnett matched four of the photos in the dataset, called “Facial droop and facial paralysis image,” to a paper published years earlier in the Journal of the Canadian Dental Association (JCDA). Only after prompting the journal to complain to Kaggle did the company take down the dataset.
Continue reading Kaggle removes problematic stroke dataset for copyright infringement






{kind=link}