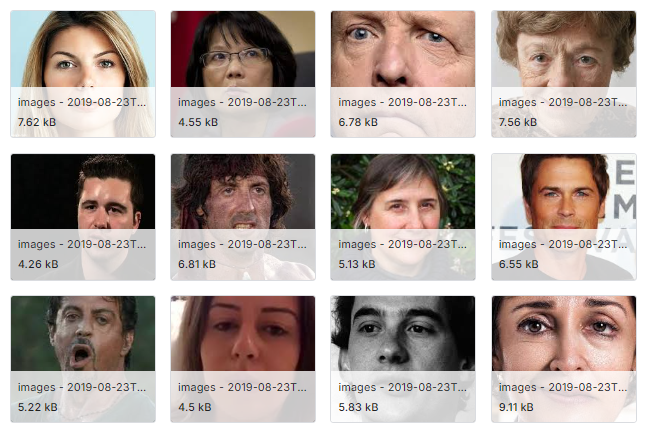
Scrolling through an online image dataset, Adrian Barnett, a statistician at the Queensland University of Technology in Australia, pointed out a few familiar faces. Sylvester Stallone as Rambo, and then again on the red carpet. “This is just ridiculous,” Barnett said. George Clooney, Angelina Jolie and Daniel Craig all appear more than once, often with the same image. “You can see,” Barnett said, “this is just a comically bad dataset.”
This particular dataset, collected in a folder titled “droopy” and hosted on an open-source repository called Kaggle, underpins a paper published in Scientific Reports – not as a find-the-celebrity game, but as a training set for a predictive clinical model for early detection of strokes.
The paper is the most recent example of a much wider problem that Barnett and his Ph.D. student Alexander Gibson have documented with Kaggle, which is owned by Google and hosts datasets uploaded by users that researchers and machine learning practitioners can use to build predictive models. By examining two other Kaggle datasets on stroke and diabetes, both of which included tabular patient data, Gibson and Barnett traced how the data move through the scientific literature and in some cases, into clinical use. Their work, described in a preprint posted to medRxiv in February, already has led to several retractions of the papers using these dubious datasets.
After trawling through so many questionable datasets for the work leading to the preprint, Gibson said the Scientific Reports paper was easy to find. “I just searched ‘Kaggle’ and ‘stroke’ in Google Scholar,” Gibson said. “This was just one of the first ones that came up.” The paper, published in December, uses two datasets purporting to show images of people who have had a stroke to train a model to detect stroke in real time and facilitate “rapid clinical intervention,” per the paper. One of the datasets has since been removed from Kaggle.
In the “droopy” dataset, which remains online, Barnett and Gibson found through reverse image search that many images were depicting Bell’s palsy, alongside images of children and infants (and celebrities). On Kaggle, the creator claims the dataset contains 1024 images of “different patients,” despite the obvious duplications, and states it is for educational purposes. “This is clearly not suitable for serious research, it’s ethically and scientifically inappropriate,” Barnett said. “There’s no reason that this should have been used given basic checks.”
After we reached out to Springer Nature, the journal added an editor’s note on the paper warning readers about concerns regarding the reliability of data in the article, and that further editorial action might follow their investigation. The corresponding author of the article, Alaa Mohamed, of Mansoura University in Egypt, did not respond to our request in time for publication.
Kaggle has faced scrutiny about data reliability before. In December, The Transmitter reported Springer Nature had taken action on nearly 40 publications that trained models with datasets that used children’s faces without consent or verification.
For the researchers, this latest discovery is just one example of a problem that they say possibly extends to thousands of papers across several online data repositories. Gibson first ran into the questionable data while searching for clinical prediction model datasets for his Ph.D. He quickly found Kaggle and the numerous datasets hosted there. “Then I thought, ‘Where did they come from?’” he said. “And kept looking, and kept looking and there was no information at all.”
To describe the issue, Gibson and Barnett focused on two datasets, one on stroke and one on diabetes, and identified 124 published papers that built models based on these datasets. Both of them failed to pass a checklist covering the who, when, where and why of data provenance in clinical predictive models, they reported on medRxiv.
Anybody doing basic checks on the datasets would have seen instantly that they do not look like real data, Gibson said. Their findings, covered in a Nature news story in April, detailed how the datasets contained thousands of duplicated patient observations, and had very few missing values, which is unlikely in a dataset containing real-world patient data.
When Gibson and Barnett raised these concerns on PubPeer, one of the authors of a paper drawing on the Kaggle data responded by citing 25 other articles that had used the same dataset. “Its continued presence in current literature indicates that it remains a commonly accepted resource for experimental evaluation in this research area,” Naeem Ramzan, the corresponding author, wrote.
That paper, published in Scientific Reports, was retracted in April because the authors couldn’t provide information about the provenance or accuracy of the data, according to the notice. “I’m not really very sympathetic to anybody who used this data thinking it was real,” Gibson said, “because they didn’t do the basics.”
The majority of the studies flagged in the preprint made practical recommendations for using the models on patients, and most of them contained no ethics statement. At least two of the models have a publicly available website, and one is linked to a medical device patent registered to the California Institute of Technology and the University of Southern California. One article states the model it describes would be used at a hospital in Indonesia, another claimed its model had successfully diagnosed a stroke and in yet another, the authors said they were deploying their model in a local heart clinic.
Several of the papers attempted to identify where the stroke data had come from; two referenced clinics in Bangladesh, another said “prestigious healthcare organizations” such as AIMS and WHO, another said clinical volunteers, and another McKinsey & Company electronic health records. Most of them are “clearly lying,” Barnett said, “because they said the dataset came from different sources.” One paper acknowledged the lack of provenance information, but still made clinical recommendations.
Ben Van Calster, a biostatistician at KU Leuven who helped develop the guidelines for data provenance, said the findings weren’t surprising. “The paper explains the problem very clearly and in depth,” he told Retraction Watch. Van Calster’s work has documented similar problems in prediction models for COVID-19, finding the majority carried a high risk of bias, with image-based models in particular having the worst issues with data quality.
Eleven of the papers using the questionable datasets are published in Springer Nature journals. Three of them, in Scientific Reports, were retracted because the authors couldn’t provide information about the provenance or accuracy of the data. Another three in the journal are under investigation.
Tim Kersjes, head of research integrity at the publisher, said its investigations are ongoing. “We will take further editorial action as appropriate on a case-by-case basis,” he said in a statement, adding that authors should have sufficient time to respond to the concerns. A spokesperson for Elsevier, whose journals have published nine of the flagged papers, said it would investigate the matter. MDPI, whose journals have published 11 of the papers, said it is aware of the issue, and that its investigation into the papers is ongoing.
Barnett and Gibson said all the online tools based on these datasets should be removed until their provenance can be confirmed, and all 124 articles should have expressions of concern.
“Of course, repositories cannot really control whether everybody uses this data in the way that they should be used,” Van Calster said. “So I think the repositories should improve their documentation.”
A spokesperson for Kaggle said the platform relies on community self-reporting for metadata and provenance. The use of synthetic data on Kaggle is “entirely legitimate,” they said, but “these datasets are intended for benchmarking and development — not as primary evidence for medical research or decision-making.” The spokesperson said the datasets from Barnett and Gibson’s preprint do not violate their terms of service, and that they would be removed if they had.
When Gibson reported his concerns about the misuse of the datasets to Kaggle, a representative said they were working on ways to better highlight synthetic data. “It’s unclear what response you are looking for from this request,” the representative added, in a chat exchange we have seen.
Barnett and Gibson found the articles they identified have been referenced in 86 review articles. “There’s a kind of laundering effect there,” Barnett said. Once these papers appear in a meta analysis, “very few people go back to look.”
Barnett and Gibson say the pressure to publish, as well as Kaggle’s incentive structure, are all part of why these questionable models are proliferating. The platform rewards users who upload popular datasets with rankings and badges, which people might use on their CVs, Barnett said.
Gibson said his list of questionable datasets continues to grow. “It’s pretty simple,” Gibson said. “Do you care about the patients or a paper?”
Like Retraction Watch? You can make a tax-deductible contribution to support our work, follow us on X or Bluesky, like us on Facebook, follow us on LinkedIn, add us to your RSS reader, or subscribe to our daily digest. If you find a retraction that’s not in our database, you can let us know here. For comments or feedback, email us at [email protected].
Jean-Claude Van Damme is jealous and urged that any paper using this dataset should be retracted. Otherwise, he’s going to blow a fuse.