
Recently, a biostatistician sent an open letter to editors of 10 major science journals, urging them to pay more attention to common statistical problems with papers. Specifically, Romain-Daniel Gosselin, Founder and CEO of Biotelligences, which trains researchers in biostatistics, counted how many of 10 recent papers in each of the 10 journals contained two common problems: omitting the sample size used in experiments, as well as the tests used as part of the statistical analyses. (Short answer: Too many.) Below, we have reproduced his letter.
Dear Editors and Colleagues,
I write this letter as a biologist and instructor of biostatistics, concerned about the disregard for statistical reporting that is threatening scientific reproducibility. I hereby urge you to spearhead the strict application of existing guidelines on statistical reporting.
As you know, the scientific community is shaken by the unanswered problem of irreproducibility, one aspect of which is the ubiquitous misuse of biostatistics in publications. Statistics serve more purposes than the sole analysis of noisy data: the statistical lexis enables an exchange of knowledge and helps communicate in a standardized manner and careless statistical reporting may endanger reproducibility. In the following, I introduce two of these mistakes that are, alas, shockingly hard to die but that you can help eradicate through simple measures.
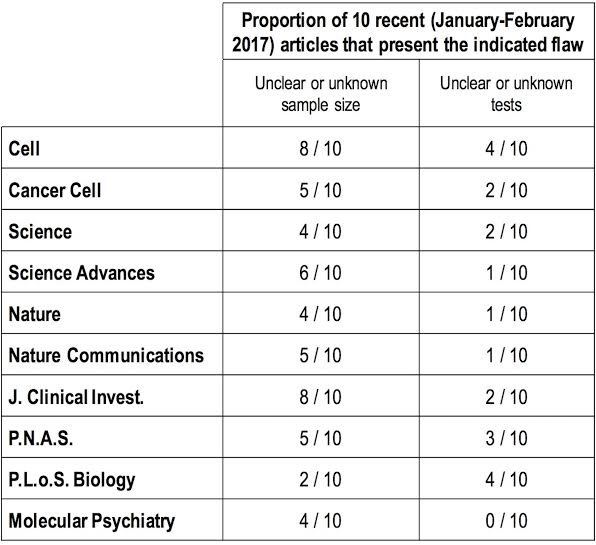
The safe-conducts given by the editorial system to articles that do not disclose exact sample sizes are shocking. Science must be based on the possibility to repeat comparable designs, which obviously encompasses the use of similar numbers of observations. Sample sizes given as intervals (e.g. “n=3- 18”), inequalities (e.g. “n>3”) or absurdly nebulous sentences (e.g. “n=4, data representative of 3 rats from 2 independent experiments”) are evident obstructions to reproducibility.
Similarly, it is perplexing to notice the proportion of publications that do not clearly reveal the statistical tests used. A clear attribution of tests must be given, including the post-hoc tests used after analysis of variance. It should not be sufficient to list all statistical procedures in the method section with no indication of which test was used in which figure or table.
The solution is simple: Enforce rigorous policies, policies that often surprisingly exist already in your guidelines for authors. The articles you publish should clearly indicate exact sample sizes that correspond to the number of independent observations as well as the tests used in each analysis. These recommendations are inexpensive and not time or staff-consuming.
I am perfectly aware that editorial policies have improved in the past couple of years, to your credit. However, a superficial skimming through recent articles published in your periodicals on January or February 2017 suffices to notice that the bad habits I have emphasized in this letter have largely outlived all guidelines (see table, below). Such flaws are unworthy of the scientific quality of your journals. Various astute suggestions have been made by others to improve reproducibility. For instance, it is essential to address publication bias, misuse of p-values, use of ridiculously small sample sizes and chronic oversight of corrections for multiple comparisons that inflates the rate of false positives…etc.
However, researchers like you and I know, that at the simple mention of such changes, protests are heard regarding the unbearable costs, in terms of money, workforce or ethics. Every scientist wants sound and reproducible science and is ready to embrace new conducts. But she/he is also justifiably reluctant to be a lonesome reformist that engages more time and money while threatening her/his chances of publication.
Unless we start by the simplest and less expensive issues enacted by collective policies, the scientific community will keep dragging their feet and all these gesticulations will be in vain.
I am mindful that, through this letter, I might eventually incur storms of protests since changes are rarely welcomed with enthusiasm. I am also aware that my non-academic affiliation might bring about skepticism. But scientific reproducibility is an enterprise important enough to outshine individual comfort.
I truly have confidence that we have a shared vision on scientific reproducibility and that you will subscribe to the content of this letter. I sincerely hope that, as editors of highly influential journals, you will take a leading role in this important transition.
The articles included in the table are listed here.
Like Retraction Watch? Consider making a tax-deductible contribution to support our growth. You can also follow us on Twitter, like us on Facebook, add us to your RSS reader, sign up on our homepage for an email every time there’s a new post, or subscribe to our daily digest. Click here to review our Comments Policy. For a sneak peek at what we’re working on, click here.
I suspect that there are several reasons that journals don’t “enforce rigorous policies, policies that often surprisingly exist already in your guidelines for authors” when it comes to problems with statistics:
1. Few authors—and frankly, few journal staff members—read journals’ guidelines for authors.
2. Few authors like change. They want to continue writing their articles in the way that their supervisors taught them.
3. Journal editors at all levels (from editors-in-chief to the self-employed editors journals contract with to do the nitty-gritty editing) may not have enough training in statistics to catch problems.
TRUTH. But to your third point, is that any excuse? It we don’t understand the sample size or the tests performed, what do we really understand about the paper? I think this letter is an important one. I’ve shared it with my Editors to make sure we are publishing the clearest information possible.
Oh, goodness, lack of training in statistics is no excuse at all. It’s something to be remedied!
Important letter and couldn’t agree more with the statement,but it’s incredible the irony that while criticizing the way statistical data is collected and reported he presents a nebulous analysis with the “proportion of ten” articles without making clear the sample size and criteria for selected articles.
Good point. I fully agree that my letter does not fulfill the strict criteria for a quantitative study and was not written as such. A deep reflexion was made on whether including the table or not. But the objective of the survey is not to give an interval and a point estimate of the true extent of flaws but rather to give a gross outlook of the current situation. The two flaws incriminated should be absent and therefore the numbers should be 0 everywhere; since it is not the case (and far from it) the conclusion is that much effort is left to be made. But I fully agree that a strict quantification would be useful… I have made it 4 years ago already as a cross sectional study, was rejected from all journals I submitted it to. Surprising? Not really. RD Gosselin
I never had statistics, but even I know that if you don’t have the size of sample, you don’t know what you’ve learned – if anything.
Not really. In this case he isn’t making an assertion about overall prevalence, he’s just making an existential statement. He could have been more specific, but it appears he looked at the first ten articles in each journal in the month. So his sample size is 10 from each journal. But again, he doesn’t make any statistical claim, only an existence claim.
The problems with credibility of published research is not new. More than a decade ago John P. A. Ioannidis published very interesting analysis on the subject (Ioannidis JPA (2005) Why most published research findings are false. PLoS Med 2(8): e124.)
More recently, another group (Steen RG, Casadevall A, Fang FC (2013) Why Has the Number of Scientific Retractions Increased? PLoS ONE 8(7): e68397.) commented “Lower barriers to publication of flawed articles are seen in the increase in number and proportion of retractions by authors with a single retraction.
Dr. Romain-Daniel Gosselin presented a concise data set which essentially demonstrates that scientist and leading journals editors continue to ignore principles of good science.
This won’t help much
Very well stated and I agree completely. Another issue that should be of great concern is drawing general conclusions based on the “statistical” analysis of small differences between replicate samples taken from the same cell suspension. All this indicates is how accurately one can pipette, rather than making valid conclusions between a number of independent derived specimens all treated similarly. This is a common fault in publications involving in vitro studies.
This is exactly in line with what Dr. Doug Altman from BMJ is fighting for !
While the author is right and the problem is real, this argument suffers from a similar problem to the one it is trying to illuminate: 1) Nowhere is the method for selecting the journal articles for analysis explained. 2) How do we know that the small sample of 10 articles from each journal is enough to quantify the problem?
I fully agree and I will paraphrase the reply I made to another close comment 🙂 Indeed, my letter does not fulfill the strict criteria for a quantitative inferential study, but it was not written with this intention. But the objective of my survey is not to give an interval and a point estimate of the true extent of flaws in the general literature (inference), but rather to give an unrefined outlook of the current situation: i.e. “whether the pointed flaws still exist or not”. The two mistakes should be absent and therefore the numbers should be 0 everywhere in the table; it is not the case. But I fully agree that a strict quantification would be useful… I performed it 4 years ago under the form of a cross sectional study… it was rejected from every journals I submitted it to. Not really surprising. RD Gosselin
Just bump onto that old post randomly. Wow! Nothing seems to have changed in the last 5 years! Papers still with bad stat presentation. I did a Pubmed search on the author’s name, and I think that’s a paper he wrote since his open letter: https://www.nature.com/articles/s41598-021-83006-5
At leat he’s tenacious!