
Finding papers produced by paper mills has become a major headache for many of the world’s largest publishers over the past year, and they’re largely playing catch-up since sleuths began identifying them a few years ago. But there may be a new way: Earlier this month, Adam Day, a data scientist at SAGE Publishing, posted a preprint on arXiv that used a variety of methods to search for duplication in peer review comments, based on the likelihood that paper mills “create fake referee accounts and use them to submit fake peer-review reports.” We asked Day several questions about the approach.
Retraction Watch (RW): Tell us a bit about the methods you used.
Adam Day (AD): This all started when an eagle-eyed editor at SAGE Publishing noticed that 2 different referees had left identical comments on 2 different peer-reviews. That seemed like a sure-sign that someone was attempting to game our peer-review system and it gave us the idea to survey our peer-review comments for more cases like this.
Initially, we treated the problem as being much like a plagiarism search. Just like when we search for plagiarism, we have a big collection of documents and we are looking for duplication of text in documents written by different authors. Most publishers are familiar with plagiarism-detection tools like iThenticate. However, after researching a long list of plagiarism-detection tools, none were found that were ideally suited to the task. We didn’t want to reinvent the wheel, so we built and tested some simple search methods. These are easy to implement and so we hope that the preprint helps others to perform the same searches.
We used tools like Elasticsearch, RapidFuzz and Locality Sensitive Hashing which worked well. Interestingly, one effective method to find partial-duplicate comments was to simply look for duplicate sentences containing typos or grammatical errors. It’s rare for 2 referees to write the same sentence, but making the same error in that sentence is no coincidence.
RW: What percentage of peer reviews were found to be suspicious? Did it tend to be one suspicious review per paper, or multiple?
AD: We need to be careful about what we term ‘suspicious’. The study found referee-accounts that had produced duplicate text. However, manual work is required to be certain which accounts were duplicating text for the purpose of abuse (a lot of referees use template reports for innocent and sensible reasons).
To answer the question, though, our dataset is limited. That will create statistical bias, meaning it’s not representative of the peer-review system as a whole. However, in my opinion, less than one in a thousand of the comments were suspicious (so <0.1%).
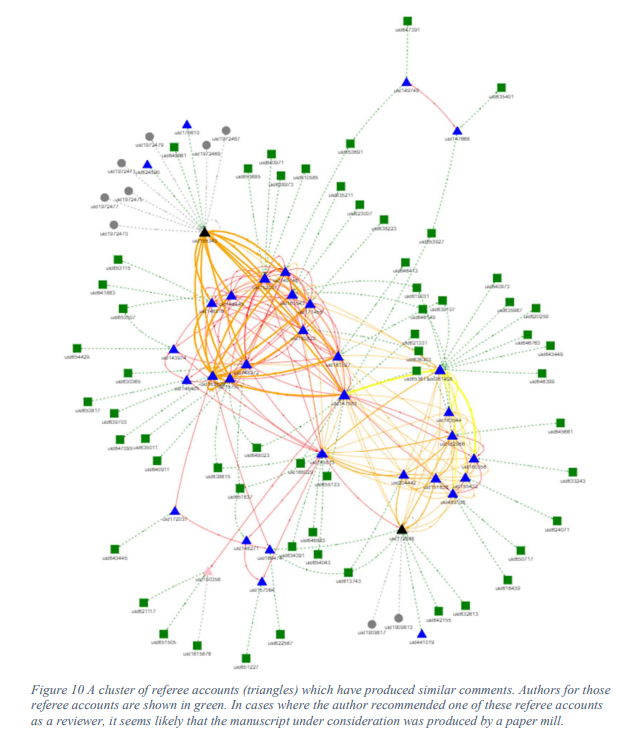
RW: How sensitive and specific are the methods? Should this be seen as a screening tool, or a diagnostic?
AD: We had intended to try a few different search methods and then pick the best one. However, the result was that all of the methods found different things. This tells us that the search methods are imperfect and won’t find every case of peer-review fraud. Furthermore, this kind of fraud only occurs in a subset of paper-mill papers, so it won’t allow us to detect all of them. Fortunately, there are better ways to do that.
However, there’s a big bonus in the network analysis. If you find just one referee who has written just one duplicate report, you can then investigate: that referee’s history, the history of every author who has ever recommended them, their co-authors, their co-authors co-authors etc. So finding just one suspicious case can be a thread worth pulling-on.
There’s potential here to create a screening tool, but it’s one of many. We have a number of much more effective methods to identify paper-mills (and misconduct more-generally). This is just another string to our bow.
I take the view that, there is no such thing as an automatable diagnostic for misconduct. This is for the simple reason that a false detection in any such system could be damaging to an honest researcher. That would be an unacceptable outcome, so a screening tool like this will flag unusual behaviour, but it won’t ever be a diagnostic. Even if it were possible to ensure a 0% false-detection rate, I don’t think it would be ethical to automate such a diagnostic.
RW: Paper mills have been known for some time. Why did you undertake this project now?
AD: We weren’t actually looking for paper mills – that result was a surprise!
SAGE has a long history in tackling peer-review fraud and so this project was essentially a continuation of that.
RW: When manuscripts are rejected by one journal or publisher, they may be submitted to another journal. Will you be sharing reviews with other publishers to cut down on “pass the paper mill, please?”
AD: At SAGE, we built our own rejected article tracker some years ago which allows us to paint a picture of where our rejected articles go. One thing that we have observed is paper mills submitting the same manuscript to multiple publishers simultaneously. This means that they can simply wait for the most lenient response from referees and proceed to publish in that journal. So this tells us that rejecting a paper mill’s manuscript is not likely to affect its prospects of publication.
There are a number of things that can happen to curtail the activities of paper mills. Publishers are already working together through initiatives such as the STM collaboration hub. The collaboration hub allows publishers to share data and collaborate with other parties to develop and operate screening tools, including those tackling paper mills.
There may be some value in sharing data from peer-review, but there are other things to do first which will have a bigger effect.
Like Retraction Watch? You can make a one-time tax-deductible contribution by PayPal or by Square, or a monthly tax-deductible donation by Paypal to support our work, follow us on Twitter, like us on Facebook, add us to your RSS reader, or subscribe to our daily digest. If you find a retraction that’s not in our database, you can let us know here. For comments or feedback, email us at [email protected].
Nice. Does SAGE deposit peer review metadata (and content), like other publishers do e.g. with CrossRef?
https://www.crossref.org/news/2018-06-05-introducing-metadata-for-peer-review/