
Nearly 100 years ago, Muriel Bristol refused to drink a cup of tea that had been prepared by her colleague, the great British statistician Ronald Fisher, because Fisher had poured milk into the cup first and tea second, rather than tea first and milk second. Fisher didn’t believe she could tell the difference, so he tested her with eight cups of tea, half milk first and half tea first. When she got all eight correct, Fisher calculated the probability a random guesser would do so as well – which works out to 1.4%. He soon recognized that the results of agricultural experiments could be gauged in the same way – by the probability that random variation would generate the observed outcomes.
If this probability (the P-value) is sufficiently low, the results might be deemed statistically significant. How low? Fisher recommended we use a 5% cutoff and “ignore entirely all results which fail to reach this level.”
His 5% solution soon became the norm. Not wanting their hard work to be ignored entirely, many researchers strive mightily to get their P-values below 0.05.
For example, a student in my introductory statistics class once surveyed 54 classmates and was disappointed that the P-value was 0.114. This student’s creative solution was to multiply the original data by three by assuming each survey response had been given by three people instead of one: “I assumed I originally picked a perfect random sample, and that if I were to poll 3 times as many people, my data would be greater in magnitude, but still distributed in the same way.” This ingenious solution reduced the P-value to 0.011, well below Fisher’s magic threshold.
Ingenious, yes. Sensible, no. If this procedure were legitimate, every researcher could multiply their data by whatever number is necessary to get a P-value below 0.05. The only valid way to get more data is, well, to get more data. This student should have surveyed more people instead of fabricating data.
I was reminded of this student’s clever ploy when Frederik Joelving, a journalist with Retraction Watch, recently contacted me about a published paper written by two prominent economists, Almas Heshmati and Mike Tsionas, on green innovations in 27 countries during the years 1990 through 2018. Joelving had been contacted by a PhD student who had been working with the same data used by Heshmati and Tsionas. The student knew the data in the article had large gaps and was “dumbstruck” by the paper’s assertion these data came from a “balanced panel.” Panel data are cross-sectional data for, say, individuals, businesses, or countries at different points in time. A “balanced panel” has complete cross-section data at every point in time; an unbalanced panel has missing observations. This student knew firsthand there were lots of missing observations in these data.
The student contacted Heshmati and eventually obtained spreadsheets of the data he had used in the paper. Heshmati acknowledged that, although he and his coauthor had not mentioned this fact in the paper, the data had gaps. He revealed in an email that these gaps had been filled by using Excel’s autofill function: “We used (forward and) backward trend imputations to replace the few missing unit values….using 2, 3, or 4 observed units before or after the missing units.”
That statement is striking for two reasons. First, far from being a “few” missing values, nearly 2,000 observations for the 19 variables that appear in their paper are missing (13% of the data set). Second, the flexibility of using two, three, or four adjacent values is concerning. Joelving played around with Excel’s autofill function and found that changing the number of adjacent units had a large effect on the estimates of missing values.
Joelving also found that Excel’s autofill function sometimes generated negative values, which were, in theory, impossible for some data. For example, Korea is missing R&Dinv (green R&D investments) data for 1990-1998. Heshmati and Tsionas used Excel’s autofill with three years of data (1999, 2000, and 2001) to create data for the nine missing years. The imputed values for 1990-1996 were negative, so the authors set these equal to the positive 1997 value.
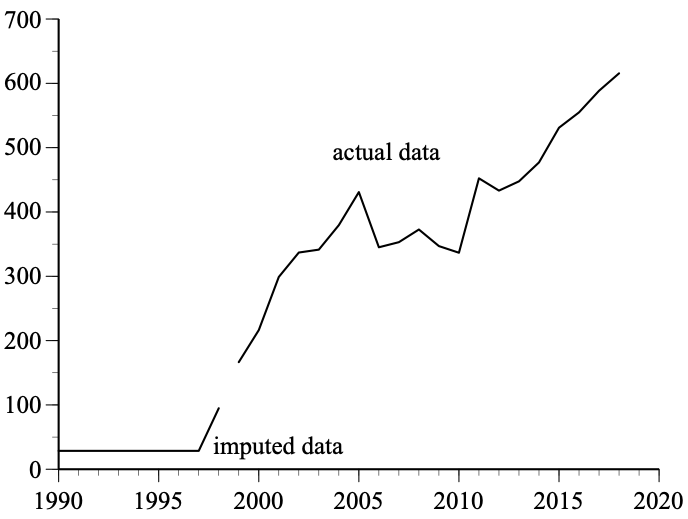
Overall, the missing observations in this data set are not evenly distributed across countries and years. IPRpro (an index of intellectual and property rights strength) is missing 79% of its data because there are only observations every four, five, or six years. Another variable, EDUter (government expenditures on tertiary education as a percentage of GDP) was said to be a “crucial determinant of innovativeness” but is missing 34% of its data.
Some countries are missing data for several consecutive years. For example, the variable MKTcap is the market capitalization of listed domestic companies measured as a percentage of gross domestic product (GDP). The MKTcap data end for Finland in 2005, Denmark in 2004, and Sweden in 2003, requiring 13, 14, and 15 years of imputed data, respectively. The MKTcap data for Greece don’t begin until 2001 (requiring 12 years of imputed data). Italy has MKTcap data for only 1999 through 2008. The authors imputed the values for the nine years before and the 10 years after this interval.
The most extreme cases are where a country has no data for a given variable. The authors’ solution was to copy and paste data for another country. Iceland has no MKTcap data, so all 29 years of data for Japan were pasted into the Iceland cells. Similarly, the ENVpol (environmental policy stringency) data for Greece (with six years imputed) were pasted into Iceland’s cells and the ENVpol data for Netherlands (with 2013-2018 imputed) were pasted into New Zealand’s cells. The WASTE (municipal waste per capita) data for Belgium (with 1991-1994 and 2018 imputed) were pasted into Canada. The United Kingdom’s R&Dpers (R&D personnel) data were pasted into the United States (though the 10.417 entry for the United Kingdom in 1990 was inexplicably changed to 9.900 for the United States).
The copy-and-pasted countries were usually adjacent in the alphabetical list (Belgium and Canada, Greece and Iceland, Netherlands and New Zealand, United Kingdom and United States), but there is no reason an alphabetical sorting gives the most reasonable candidates for copying and pasting. Even more troubling is the pasting of Japan’s MKTcap data into Iceland and the simultaneous pasting of Greece’s ENVpol data into Iceland. Iceland and Japan are not adjacent alphabetically, suggesting this match was chosen to bolster the desired results.
Imputation is attractive because it provides more observations and, if the imputed data are similar to the actual data, the P-values are likely to drop. In an email exchange with Retraction Watch, Heshmati said, “If we do not use imputation, such data is [sic] almost useless.”
Imputation sometimes seems reasonable. If we are measuring the population of an area and are missing data for 2011, it is reasonable to fit a trend line and, unless there has been substantial immigration or emigration, use the predicted value for 2011. Using stock returns for 2010 and 2012 to impute a stock return for 2011 is not reasonable.
Clearly, the more values are imputed, the less trustworthy are the results. It is surely questionable to use data for, say, 1999 through 2008 to impute values for 1990-1998 and 2009-2018. It is hard to think of any sensible justification for using 29 years of one country’s data to fill in missing cells for another country.
There is no justification for a paper not stating that some data were imputed and describing how the imputation was done. It is even worse to state the data had no missing observations. This paper might have been assessed quite differently – perhaps not been published at all – if the reviewers had known about the many imputations and how they were done.
Gary Smith is an economics professor at Pomona College. He has written (or co-authored) more than 100 peer-reviewed papers and 17 books, including the best-seller Standard Deviations: Flawed Assumptions, Tortured Data, and Other Ways to Lie With Statistics.
Like Retraction Watch? You can make a tax-deductible contribution to support our work, subscribe to our free daily digest or paid weekly update, follow us on Twitter, like us on Facebook, or add us to your RSS reader. If you find a retraction that’s not in The Retraction Watch Database, you can let us know here. For comments or feedback, email us at [email protected].
When you impute data like this, you are assuming your conclusion. “Well, the data is going to be similar, so I’ll just make it up along the same pattern.” It’s a basic logical fallacy
I liked this article about whether you should put the milk in the tea first or last. Real science by a pioneer of statistics – milk timing makes a difference but the story doesn’t say which way the difference is! From my past mistakes I wondered whether this should be a two tailed test or one tailed. 😂
https://retractionwatch.com/2024/02/21/how-not-to-deal-with-missing-data-an-economists-take-on-a-controversial-study/
I concur- “This paper might have been assessed quite differently – perhaps not been published at all – if the reviewers had known about the many imputations and how they were done.”
Very informative post that should be part of any civics, ethics, and/or science course work in high school!
Fully agree. There are, however, quite acceptable ways of imputing data that take into account the uncertainty of the imputed data. This is often better than using the complete data only (for example by deleting the cases with missing data). Paul Allison has a nice book on missing data: https://doi.org/10.4135/9781412985079. Of course, being transparant on what you’ve done is key.
Wow. Inserting 29 years of MKTcap data from Japan into the non-existent data from Iceland. Two ‘island’ economies with extreme population & economic & cultural differences. And we wonder why these types of studies generate conclusions that are not sustainable… I think that some fields need to serioualy lift their game on ‘best practices’. These statistical shenanigans sound like high school & early year university hi-jinks…
Yes, but Japan IS alphabetically close to Iceland…
Of course they are close to each other in the English language but in the original Island is far removed from Nippon.
Perhaps they assumed that since Iceland and Japan are both volcanic islands that they would share other features too…
I have question for the group – especially the statisticians. At what point does the data become useless or dubious in terms of missings? Where is the line drawn – at 20% missing?
There is no magic threshold. It depends at least on:
* the type of missingness (missing completely at random, missing at random, missing not at random)
* the distribution of missing values over the variables, over time, over space, …
* the questions you ask the data and the statistical methods you want to use
Ultimately, you need to quantify and assess the uncertainty (and possibly even bias) arising from imputation for the specific data and the specific analysis.
Morning H.
I used to go to Marty, a Phd Statistician from UC Berkeley, when I had questions around sample sizes, random vs selected sampling protocols and the like. He designed the clinical trials for the firm I worked at decades ago and he wrote the software code to evaluate system performance using the reference measurement systems he validated for post market surveillance of products in LOTUS 123.
Marty’s mind worked a lot like Roland Fryer’s- see his discussion with B. Wise
https://whyevolutionistrue.com/2024/02/21/bari-weiss-interviews-roland-fryer/
on the type of questions one might want to ask BEFORE doing any statistics.
I recall, fondly now, the time required for testing some Lotus 123 software code against results generated with a HP calculator and by hand for a variance measurement of disposable strip lots.
Neat story about the tea–as an econ grad student I unknowingly did the same thing with coke zero when it was reformulated. (10/10).
I have always found data imputation to be fishy because the same conditions tbst make it reliable make it unnecessary. If you can predict Japan’s 1997 GDP from Japan in 1996 and 1998 then adding 1997 to the data should not add new information or change your estimates. It should not even make your effective sample size go down if you are properly clustering standard errors. Imagine a cheeky undergrad like yours who, given a country-year dataset, copied each value 365 times and claimed the unit was the country-day.
One might object that the data contains enough information to approximate Japan in 1997, if not predict it exactly, and ignoring this information is a waste. But the only way that can be true is if you’re willing to make assumptions about the data, e.g., Japan 1997 is highly correlated with Japan 1996 and 1998 or Japan in year t is correlated with some other country in year t. In that case: why not build the assumption into the model itself?
Censored models, Heckman style selection models, synthetic control, and certain Bayesian models are examples of how you can build assumptions about missing data into the estimator itself.
In some cases this may not be practicable or worth the effort when the number of missing observations is small and the analysis is complex or relies on inflexible software. Even in those cases, the researcher needs to be transparent about the assumptions behind the imputation and provide robustness tests or some adjustments of standard errors. If a researcher claims imputation is necessary to get a statistically significant result, then that’s a huge red flag.
Fascinating story. But I wonder what other justification could there be for copying data from one country to another other than its alphabetical order? Perhaps similar colors on the flags of countries or the number of lakes per inhabitant.